
Real-Time Embodied Agent with LLM and TurtleBot3
Large language models (LLMs) are increasingly applied in real-world scenarios, we set out to create an embodied agent by integrating Ollama's large language model with a TurtleBot3 and ROS, allowing the robot to navigate autonomously based on user input. The motivation of this project was to enhance interactions with robotic agents, enabling individuals with speech impediments, like stuttering or aphasia, to communicate more easily with at-home robots. The project also provided valuable insights into the improvements needed to develop reliable embodied agents.
My role: Self-initiated project in collaboration with Hassam Khan Wazir at NYU Mechatronics and Robotics Lab; Contributions: Conception of idea, Coding (LLM-Python-Turtlebot 3 communication, running LLM via hugging face), and Demoing actions on live robot.
Status: Completed Project (Live demo below), Github
Initial Idea & Inspiration
Sketch/Prototype: Use AI prompting to control a humanoid toy robot with user commands instead of a remote. The initial plan was to use user gestures detected by a camera to prompt the robot.
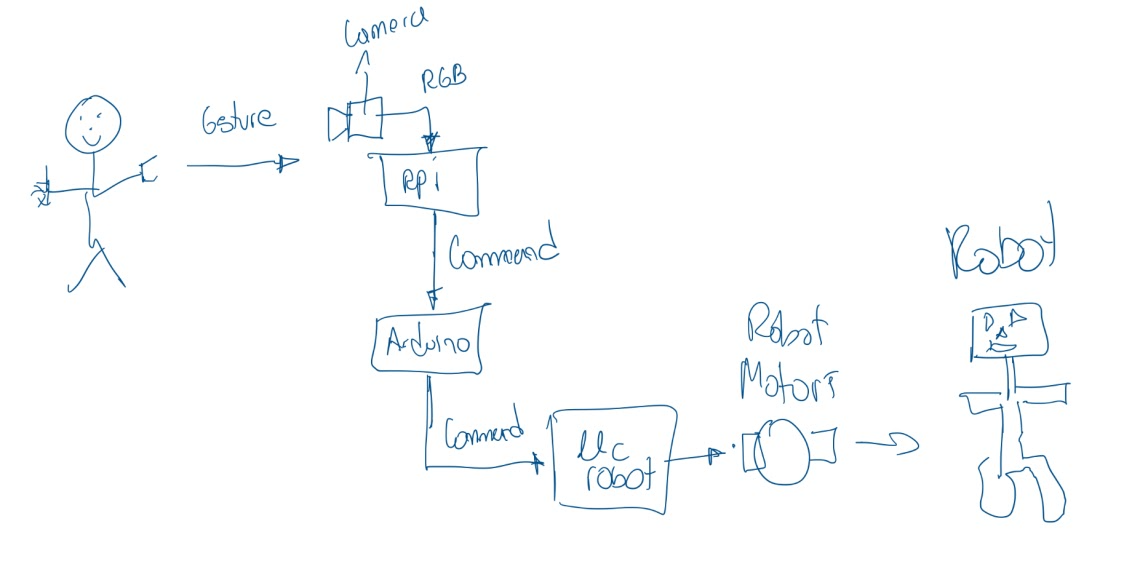
Unity Demo: Due to the physical effort required for gesturing and the gesture sensor's inconsistent response, we shifted to an LLM model, allowing users to type commands for the robot to follow. I prototyped this idea in Unity with Hugging Face's Jammo API
LLM and Arduino: We used Ollama's LLM model. It was able to interpret a command from the prompt and then send a corresponding IR signal to the Arduino so the robot could pick up the signal and execute the corresponding command
Commanding the robot with the remote
Commanding the robot with LLM and IR Signal
Limitations: The toy robot's IR receiver was weak, causing inconsistent responses to each command. This made it difficult to send a sequence of IR signals for the robot to follow multiple instructions in order. So we pivoted to using a more advanced robot that we had more control over.
TurtleBot and ROS
New Approach: To simplify the problem we reduced the actions of the robot so it can only "step forward", "turn left", or "turn right". We set up ROS Humble on the Raspberry Pi 4 embedded in the robot. We configured the Turtlebot3 ROS packages to manage the robot's movement through ROS then built a custom ROS package to allow the robot to receive and execute instructions from the LLM.

Execution: We used the Llama-3.1-70B model, the smallest in the Ollama framework capable of generating accurate navigation paths for the robot. To execute this, we set up a Hugging Face space with Gradio and wrote a Python script to communicate with the model and relay its instructions to the robot. The model was not fine-tuned, but we utilized a system prompt to ensure the LLM understood the task.
System Prompt
You are controlling a 2 DOF robot on a 50x50 grid. The robot can move one step in any of the four cardinal directions. The robot can perform the following actions:
- 'up': Move one unit up (increasing y coordinate by 1).
- 'down': Move one unit down (decreasing y coordinate by 1).
- 'left': Move one unit left (decreasing x coordinate by 1).
- 'right': Move one unit right (increasing x coordinate by 1).
Given a target coordinate, your task is to calculate and output the shortest sequence of commands that will move the robot from its current position to the target position.
Output Format:
- Begin with the exact phrase: 'The full list is:'.
- Provide the sequence of commands as a JSON array, with each command as a string. Commands must be exactly 'up', 'down', 'left', or 'right'.
- All coordinates should be formatted as JSON objects with keys 'x' and 'y' and integer values. For example, the starting position should be output as {'x': 0, 'y': 0}.
- When calling tools, ensure that all arguments use this JSON object format for coordinates, with keys 'x' and 'y'.
- Example of correct output: If the target coordinate is {'x': 2, 'y': 3}, your response should include: 'The full list is: ["right", "right", "up", "up", "up"]'
Please ensure that all output strictly adheres to these formats. If any output is not in the correct format, redo the task and correct the output before providing the final answer.
Prompts:
The appeal to using a detail system prompt was so we could make the user prompt quite simple. Specifying that the robot's original oriention is facing "north" below is a sample user prompt:
"The robot is at 'start_position': {'x': 25, 'y': 24}. What is the shortest list of actions to take in sequence to get to 'target_position': {'x': 27, 'y': 25}? "
The above user prompt combined with the system prompt resulted in the following LLM response:
Model Response: [["The robot is at 'start_position': {'x': 25, 'y': 24}. What is the shortest list of actions to take in sequence to get to 'target_position': {'x': 27, 'y': 25}?". 'The full list is: ["right", "right", "up"].']]
Demo
Result: The robot performed successfully on all the test cases we tried. Future improvements in this work include employing the robot's other senses to provide feedback during task execution and finetuning a smaller LLM model so it can work with a similar degree of success as the Llama-3.1-70B model.
Future/Challenges/Learnings: Despite the rise of open-source language models, accessing the resources needed to work on in-depth projects with emerging technologies at home remains a challenge. For example, I had limited GPU capacity on my computer to run a sophisticated version of the model necessary to answer carry out this project alone. This project highlighted the potential to empower individuals with cognitive or motor impairments through AI-driven systems that enhance or replace sensory experiences. I hope to gain access to advanced AI resources and GPUs and further explore human-technology interaction, especially for those with sensory or motor limitations. My goal is to design systems that capture richer sensory input from users, expanding accessibility and enhancing the depth of their interaction.